Multi-Turn
Evaluation LLM Conversations
Analyze, measure, and improve AI agent conversations with structured evaluation workflows and hierarchical insights.

Three-Level Hierarchy
TurnWise organizes conversations into a hierarchical structure, enabling evaluation at any granularity level.
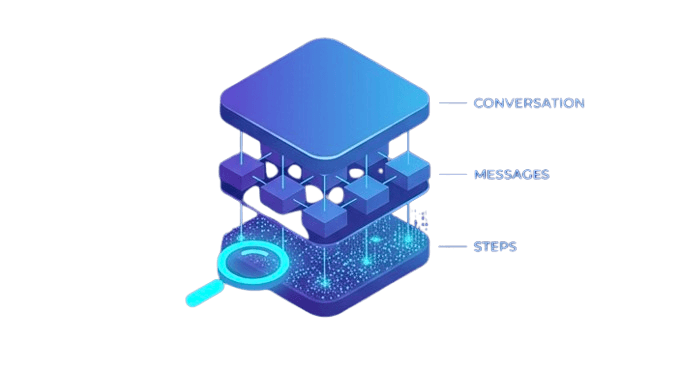
Conversation
A complete multi-turn dialogue between users and AI agents. Evaluate the entire conversation flow and overall quality.
Messages
Individual messages within a conversation (user, assistant, system, tool). Analyze each exchange independently.
Steps
Individual reasoning steps within a message (thinking, tool calls, outputs). Dive deep into the agent's thought process.
Powerful Features
Everything you need to evaluate and improve your LLM conversations.
Hierarchical Evaluation
Evaluate entire conversations, individual messages, or specific reasoning steps. Create custom evaluation metrics with prompts and output schemas. Run evaluations on-demand or in batch.
Rolling Summaries
Automatically maintain compressed summaries of long conversations. Prevents context window overflow when evaluating lengthy dialogues. Incrementally updates summaries as conversations grow.
Evaluation Pipelines
Define reusable evaluation workflows (pipelines). Each pipeline contains multiple evaluation nodes (metrics). Execute pipelines across datasets with streaming results.
Data Management
Organize conversations into datasets. Track LLM calls, costs, and performance metrics. Store structured outputs and metadata for comprehensive analysis.
How It Works
Get started in three simple steps.
Upload Datasets
Import your multi-turn conversation data with messages and steps. Organize them into datasets for easy management.
Define Metrics
Create custom evaluation metrics with prompts and output schemas. Build reusable evaluation pipelines.
Run Evaluations
Execute evaluations and see results streaming in real-time. Get insights at conversation, message, or step level.
Comprehensive Evaluation Metrics
TurnWise includes a powerful set of evaluation metrics designed specifically for multi-turn LLM agent conversations. Evaluate at message, step, or conversation level.
Message Level Metrics
CCM
MessageConversation Continuity Metric - Detects when users re-ask similar questions, indicating the previous response was incomplete or unsatisfactory.
RDM
MessageResponse Dissatisfaction Metric - Identifies explicit user corrections or expressions of dissatisfaction with the assistant's response.
Step Level Metrics
TSE
StepTool Selection Error - Evaluates whether the correct tool was selected for the given task context.
PH
StepParameter Hallucination - Detects hallucinated or fabricated parameters passed to tools (e.g., invented file paths, non-existent IDs).
SCD
StepSelf-Correction Detection - Measures the agent's ability to recognize and recover from its own errors.
TUM
StepTool Use Metrics - Comprehensive multi-dimensional analysis of tool usage including selection, parameter accuracy, and result handling.
Conversation Level Metrics
TCI
ConversationTool Chain Inefficiency - Identifies redundant, circular, or inefficient sequences of tool calls.
ATA
ConversationAgent Trajectory Analysis - Analyzes conversation patterns for circular reasoning, regression, stalls, and goal drift.
IDM
ConversationIntent Drift Metric - Measures how well the agent maintains alignment with the original user intent throughout the conversation.
⚡ Basic vs Advanced Metrics
TurnWise provides two variants of each metric:
- 📌Basic Metrics: Simple prompts without template variables. Suitable for quick evaluations.
- 🚀Advanced Metrics: Use template variables like
@HISTORY,{goal},{tools}for context-aware evaluation.
📤 Output Types
Metrics can output different types of results:
Ready to Get Started?
Join TurnWise and start evaluating your multi-turn LLM conversations with powerful, hierarchical insights.